| |
| |
 |
|
| |
|
|
| |
|
|
| |
|
|
|
|
| 정
인 상 (충북대학교 국어국문학과 교수) |
컴퓨터에서의
한글 코드 문제는 한자나 특수 문자 등과 관련되어 있기 때문에 한글 단독으로만 이야기할
수 없는 문제이다. 한글과 한자 이외에도 많은 문자가 필요하게 되지만 이들은 고정적인
코드를 부여하기보다는 사용자 개개인의 특수성에 맡길 수밖에 없을 것으로 생각된다. 한글의
경우에도 고어 자형들이 약 1,000자 정도가 더 필요하며, 한자의 경우에도 그때그때의
상황에 따라 누락된 글자들이 더 필요하게 될 것이다. 또, 국어학의 면에서는 구결이나
이두문자가 100여 자 정도 더 필요하다는 것도 지적되고 있다. 이외에도 각종 그래픽
도안 문자나 일본 문자, 희랍 문자, 영어 발음 기호 등등이 사용자의 특수성에 따라서
꼭 필요한 문자가 될 것이다. 이러한 문자들을 그 필요에 따라 사용 가능하게 하기 위해서는
사용자 정의 문자 영역을 어느 정도 확보해 두고 필요에 따라서 사용할 수밖에 없을 것으로
생각된다. 필자의 생각으로는 이러한 사용자 정의 문자 영역은 최소한 1,000자 정도는
되어야 할 것으로 보아 2바이트 완성형 방식으로 하면 1,146자가 수용될 수 있을 것으로
생각된다.
지금까지의 논의를 종합하면 한글은 현행 맞춤법의 한계를 벗어나서
모두 16,399글자를 수용하게 되며, 한자는 기본적으로 4,966자를 수용하게 된다.
뿐만 아니라 만일의 경우를 대비하여 1,146자의 사용자 정의 문자 영역을 마련하였기
때문에 한자 부족분이나 한글 코드로 처리되지 못하는 옛글자 등의 실현을 위하여 완성형
코드로 활용할 수 있다. 여기에서 한글 16,399자는 고어 자모를 일부 포함한 조합형이기
때문에, 고어에 관한 한 실제로는 사용되지 않는 글자가 상당히 들어 있다. 앞으로 정밀한
검토를 거쳐서 불필요한 옛글자 조합을 제외할 수 있게 된다면, 바꾸어 말하여 필요한 옛글자
목록이 완성된다면 이들을 현행 한글과 합하여 영구적인 완성형 방식의 코드 체계도 생각해
볼 수 있을 것이다. 이렇게 하면 코드 영역을 좀더 효율적으로 사용하는 것이 되어서 한자의
수용 능력이 훨씬 늘어나게 될 것이다. 컴퓨터에서의 한글 문제는 궁극적으로 현행 한글과
옛글자, 그리고 한자를 얼마나 많이 수용하는가 하는 문제이기 때문이다. 그러나 현재로서는
현행 조합형 한글을 약간 확장하는 선에서만 논의를 하였는 바, 현행 조합형 코드 체계의
부족함을 보완하여 좀더 개선된 문자 코드 체계를 제시하면 다음과 같다.
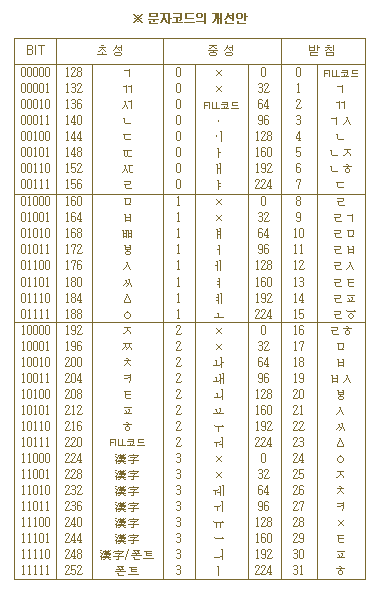
* × 표시는 MS-DOS 제약으로 사용이 불가능한 부분
* 한글 : 16,399자 (초성 23, 중성 23, 받침 30)
* 漢字 : 4,966자
* 폰트 : 1,146자 (사용자 정의 문자)
* 빈칸 : 768자 (코드 배정 제약) |
|
5 |
|
 |
|
|
|
|
|
|

